22个任务超越SOTA,43个任务媲美SOTA,Google推出医学治疗通用大模型

编辑 | 萝卜皮
如果医生和科学家想开发一种新的疗法,这将是一个漫长且繁琐的任务,需要满足许多不同的标准,而能够加快这一过程的人工智能模型将是无价之宝。
然而,目前大多数人工智能方法只能解决一组定义狭窄的任务,通常局限于特定领域。
为了弥补这一差距,Google 团队提出了Tx-LLM,这是一种通用大型语言模型(LLM),由PaLM-2微调而成,可编码有关各种**方式的知识。
使用一组权重,Tx-LLM 可同时处理与自由文本交织的各种化学或生物实体(如小分子、蛋白质、核酸、细胞系、疾病)信息,使其能够预测广泛的相关属性。在 66 个任务中的 43 个任务上实现了与**进技术(SOTA)相媲美的性能,并在 22 个任务中超越了 SOTA。
Tx-LLM尤其强大,在将分子SMILES表示与文本(例如细胞系名称或疾病名称)相结合的任务中,其平均表现优于同类**。

该研究以「Tx-LLM: A Large Language Model for Therapeutics」为题,于 2024 年 6 月 10 日发布在 arXiv 预印平台。

**开发是一个充满风险的漫长过程,据统计,90% 的候选**在临床试验阶段会失败,而那些成功的**从研发到获批上市通常需要耗费 10 至 15 年时间及 10 亿至 20 亿美元的资金。
一个有效的****必须满足多重标准,包括与目标病灶有效互动、具备良好的药效和临床疗效,同时确保**性和具有理想的**特性,如溶解性、渗透性以及合适的药代动力学等。
在临床试验中,意外的非靶向效应或**间相互作用可能会抵消原本有前景的候选**的效果。因此,**研发面临着巨大的挑战。
关于 Tx-LLM 如何工作
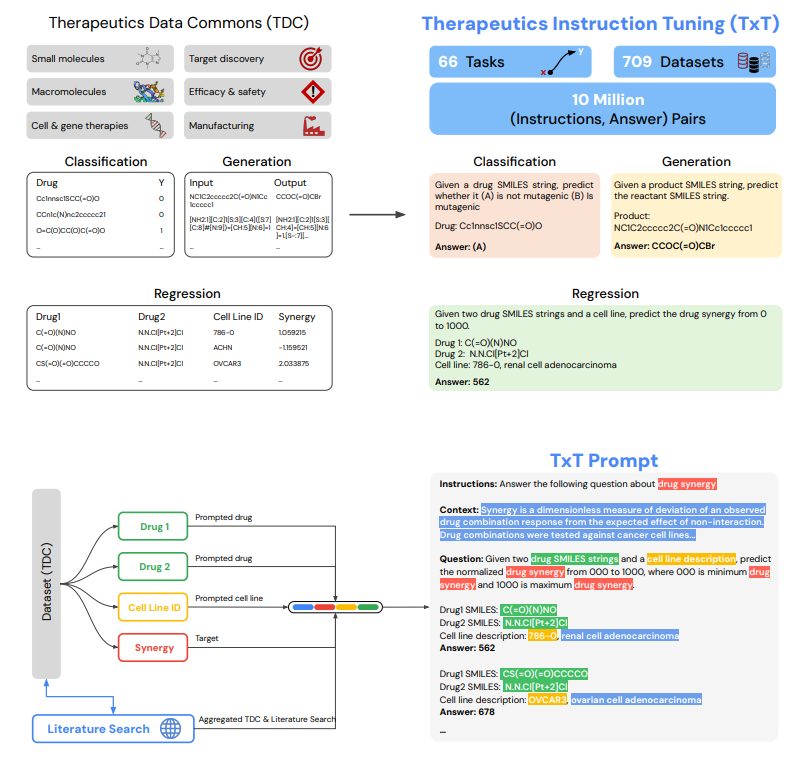
Tx-LLM,一种专为**学设计的大型语言模型,旨在加速**发现流程。该模型由 PaLM-2 训练而成,通过处理包含 709 个数据集的 TxT 集合,覆盖**发现管线中的 66 项任务,能够编码关于多种**方式的知识。这些数据集的中位数大小为 11,000 条数据点。Tx-LLM 排除了少量 TDC 数据集。
图示:Tx-LLM 概述。(来源:论文)
TxT 数据集的每个组成部分都设计成包含四部分的文本提示:指令、上下文、问题和答案。每条数据的指令是一个简短的句子,描述了要执行的具体任务,例如「回答有关**属性的问题」。
对于每一个数据集,研究者精心构造了上下文,即提供了额外的自由文本描述,用于将问题置于相关生物化学背景中。上下文通常由 2-3 句话组成,来源自 TDC 数据集的描述,并根据主题的文献检索进行了人工补充。对于描述特定实验条件的专门测试,如 ToxCast,上下文的额外信息来源于公开的测试描述。
数据集中的问题是一个简洁的询问,明确指出了所询问的特定属性,如「以下分子是否能穿过血脑屏障?」问题中**了基于文本的**剂表示。答案的格式因任务类型而异。
TxT数据集主要分为三类:二元分类问题,即预测**剂的单一属性,给出两种可能的答案,如**是否有毒性;回归问题,预测**剂在连续尺度上的单一属性,例如**与目标的结合亲和力。
为了适应基于 token 而非浮点数表示的语言模型,回归任务的标签被均匀地划分为 0 到 1000 之间的区间,指示 Tx-LLM 预测区间标签。在评估时,预测的区间标签会被转换回原始的数值标签空间。整个设计确保了 Tx-LLM 能够**地处理**发现流程中的多样化任务。
Tx-LLM 的稳健性能
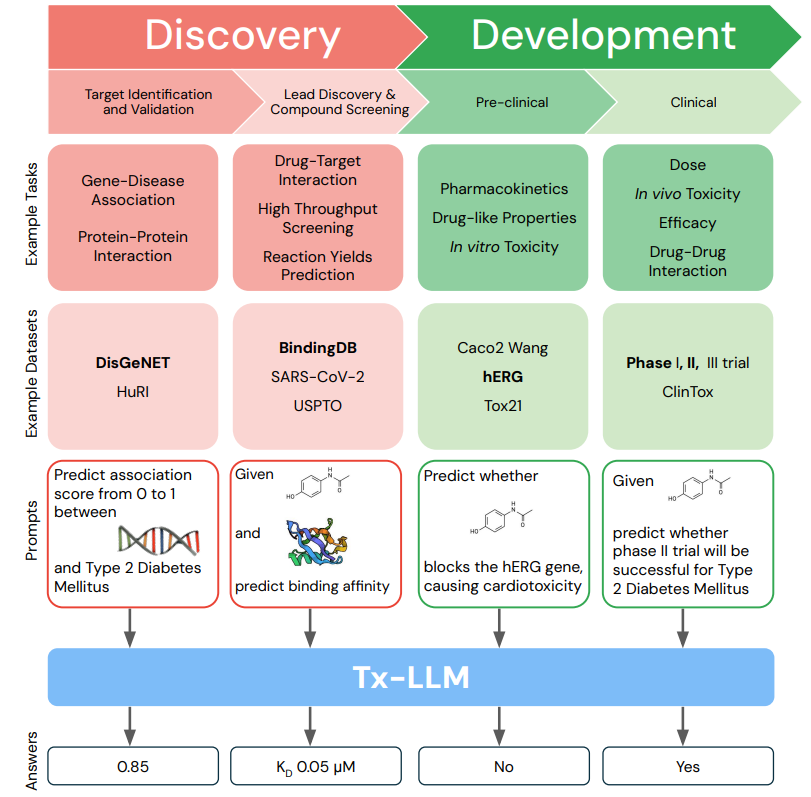
图示:Tx-LLM 可能对端到端**发展有效。(来源:论文)
Tx-LLM 使用单一权重集同时处理多样化的化学和生物实体(小分子、蛋白质、核酸、细胞系、疾病)与自由文本的组合,预测这些实体的广泛相关属性。在 66 项任务中,Tx-LLM 在 43 项任务上达到了与**进水平相当的表现,在 22 项任务上甚至超越了现有**模型。

特别是在结合分子 SMILES 表示与文本(如细胞系名称或疾病名称)的任务上,Tx-LLM 表现尤为突出,这可能得益于预训练期间学到的上下文信息。
此外,研究人员还发现了不同类型**任务之间存在正面的知识迁移,例如小分子和蛋白质任务间的相互促进。这些结果表明,Tx-LLM 是朝着将生物化学知识编码进大型语言模型方向迈出的重要一步,未来有可能在整个**发现和开发过程中扮演关键角色。
论文链接:https://arxiv.org/abs/2406.06316
相关内容:https://x.com/arankomatsuzaki/status/1800372459344114029