长文本杀不死RAG:SQL 向量驱动大模型和大数据新范式,MyScale AI数据库正式开源
作者:LR •更新时间:2025-08-05 01:58:55•阅读 0
大模型和 AI 数据库双剑合璧,成为大模型降本增效,大数据真正智能的制胜法宝。

有人认为 RAG 要被长上下文模型杀死了,但这种观点遭到了很多研究者和架构师的反驳。他们认为一方面数据结构复杂、定期变化,并且很多数据具有重要的时间维度,这些数据对于 LLM 来说可能太复杂。另一方面,企业、行业的海量异构数据,都放到上下文窗口中也不现实。而大模型和 AI 数据库结合,给生成式 AI 系统注入专业、精准和实时的信息,大幅**了幻觉,并提高了系统的实用性。同时,Data-centric LLM 的方法也可以利用 AI 数据库海量数据管理、查询的能力,大幅**大模型训练、微调的开销,并支持在系统不同场景的小样本调优。总结来说, 大模型和 AI 数据库双剑合璧,既给大模型降本增效,又让大数据真正实现智能。
历经数年开发和迭代,MyScaleDB 终于开源
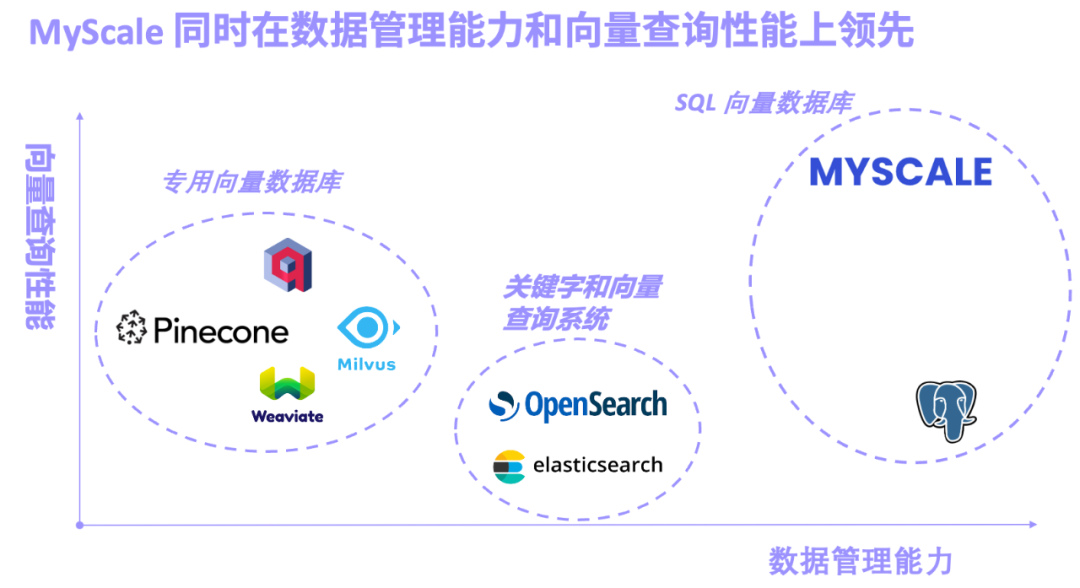
RAG 的出现使得 LLM 能从大规模的知识库中**地抽取信息,并生成实时、专业、富有洞察力的答案。伴随而来的是 RAG 系统的核心功能向量数据库也得到了迅速发展,按照向量数据库的设计理念我们可以将其大致分为三类:专用向量数据库,关键字和向量结合的检索系统,以及 SQL 向量数据库。
- 以 Pinecone/Weaviate/Milvus 为代表的专用向量数据库,一开始即为向量检索设计打造,向量检索性能出色,不过通用的数据管理功能较弱。
- 以 Elasticsearch/OpenSearch 为代表的关键字和向量检索系统,因其完善的关键字检索功能得到广泛生产应用,不过系统资源占用较多,关键字与向量的联合查询精度和性能不尽人如意。
- 以 pgvector(PostgreSQL 的向量搜索插件)和 MyScale AI 数据库为代表的 SQL 向量数据库,基于 SQL 并且数据管理功能强大。不过因为 PostgreSQL 行存的劣势和向量算法的局限性,pgvector 在复杂向量查询中精度较低。
得益于 SQL 数据库在海量结构化数据场景长期的打磨,MyScaleDB 同时支持海量向量和结构化数据,包括字符串、JSON、空间、时序等多种数据类型的**存储和查询,并将在近期推出功能强大的倒排表和关键字检索功能,进一步提高 RAG 系统的精度并替代 Elasticsearch 等系统。
项目地址:https://git**.com/myscale/myscaledb **兼容 SQL,精度提升、成本**
借助完善的 SQL 数据管理能力,强大**的结构化、向量和异构数据存储和查询能力,MyScaleDB 有望成为**款 真正面向大模型和大数据的 AI 数据库。
SQL 和向量的原生兼容性
自从 SQL 诞生半个世纪以来,尽管其中经历了 NoSQL、大数据等浪潮,不断进化的 SQL 数据库还是占据了数据管理市场主要份额,甚至 Elasticsearch、Spark 等检索和大数据系统也陆续支持了 SQL 接口。而专用的向量数据库尽管为向量做了优化和系统设计,但其查询接口通常缺乏规范性,没有**的查询语言。这导致了接口的泛化能力较弱,例如 Pinecone 的查询接口甚至不包括指定要检索的字段,更不用说分页、聚合等数据库常见的功能。
接口的泛化能力弱意味着其变化**,增加了学习成本。MyScale 团队则认为, 经过系统性优化的 SQL 和向量系统是可以既保持完整的 SQL 支持,又保证向量检索高性能的,而他们的开源评测的结果已经充分论证了这一点。
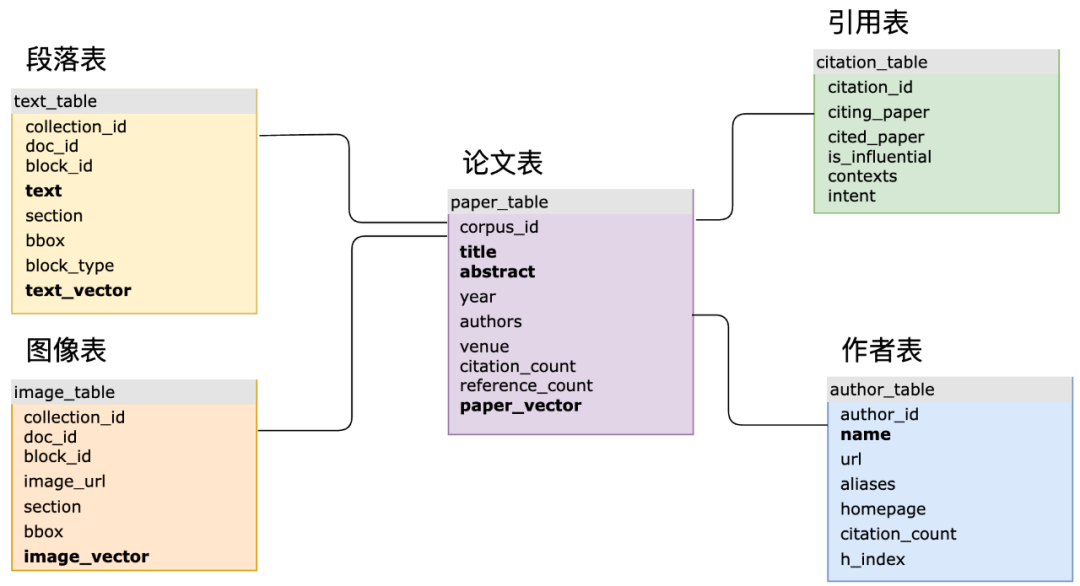
在实际复杂 AI 应用场景中,SQL 和向量结合可以极大增加数据建模的灵活性,并简化开发流程。例如 MyScale 团队与北京科学智能研究院合作的 Science Navigator 项目中,利用 MyScaleDB 对于海量的科学文献数据做检索和智能问答,其主要的 SQL 表结构就有 10 多个,其中多张表结构建立了向量和倒排表索引,并利用主键和外键做了关联。系统在实际查询中,也会涉及结构化、向量和关键字数据的联合查询,以及几张表的关联查询。在专用的向量数据库中这些建模和关联是难以实现的,也会导致**的系统迭代**、查询低效和维护困难。
在实际 RAG 系统中,检索的精度和效果是制约其落地的主要瓶颈。这需要 AI 数据库**支持结构化、向量和关键字等数据联合查询,综合提高检索精度。
例如在金融场景中,用户需要针对文档库查询 “某公司 2023 年全球各项业务的收入情况如何?”,“某公司”,“2023 年” 等结构化元信息并不能被向量很好的抓取,甚至不**在对应的段落中有直接的体现。直接在全库上执行向量检索会得到大量的干扰信息,并**系统**的准确性。另一方面,公司名称,年份等通常是可以作为文档的元信息被获取的,我们可以将 WHERE year=2023 AND company ILIKE "%

真实场景下性能和成本的平衡
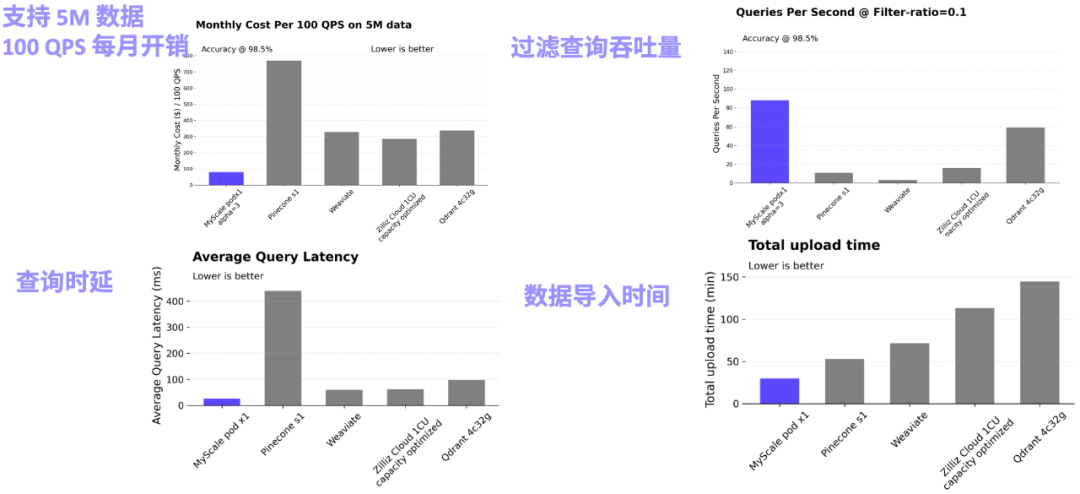
正因为向量检索在大模型应用中的重要性和高关注度,越来越多的团队投入了向量数据库这个赛道。大家一开始的关注点都是努力提升纯向量搜索场景下的 QPS,不过 纯向量搜索是远远不够的!在实战的场景中,数据建模、查询的灵活性和精准度以及平衡数据密度、查询性能和成本是更为重要的议题。
在 RAG 场景中,纯向量查询性能有 10x 的过剩,向量占用资源庞大,联合查询功能缺乏、性能和精度不佳往往是当下专有向量数据库的常态。 MyScaleDB 致力于在真实海量数据场景下 AI 数据库的综合性能提升,其推出的 MyScale Vector Database Benchmark 也是业内**在五百万向量规模,不同查询场景下比较主流向量数据库系统综合性能、性价比的开源评测系统,欢迎大家关注和提 issue。MyScale 团队表示,AI 数据库在真实应用场景下还存在很大的优化空间,他们也希望在实践中不断打磨产品并完善评测系统。
MyScale Vector Database Benchmark 项目地址: https://git**.com/myscale/vector-db-benchmark
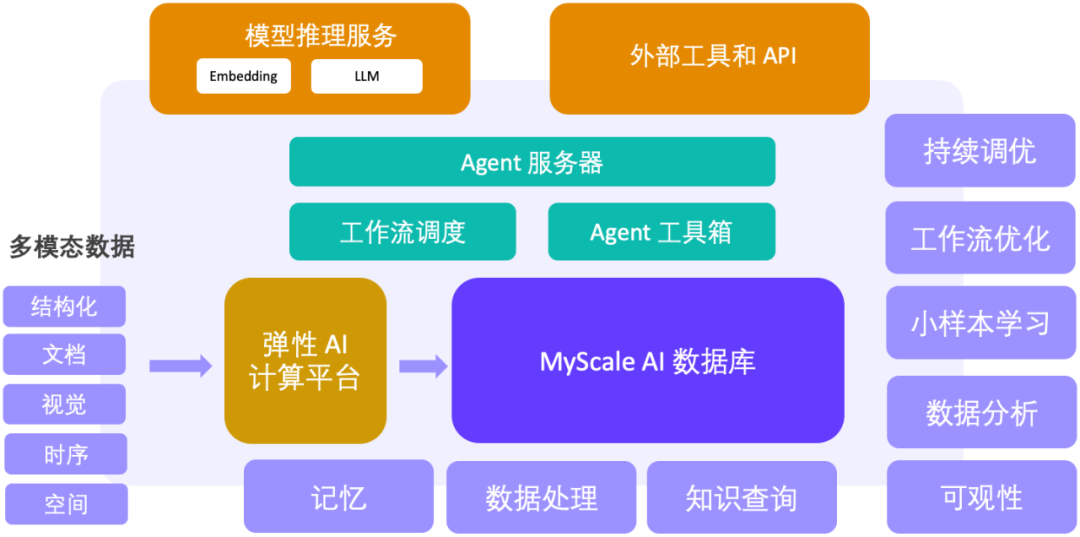
展望:AI 数据库支撑的大模型 大数据 Agent 平台
机器学习 大数据驱动了互联网和上一代信息系统的成功,而在大模型的时代背景下,MyScale 团队也致力于提出新一代的大模型 大数据方案。以 高性能的 SQL 向量数据库为坚实的支撑,MyScaleDB 提供了大规模数据处理、知识查询、可观测性、数据分析和小样本学习的关键能力,构建了 AI 和数据闭环,成为 下一代大模型 大数据 Agent 平台的关键基座。MyScale 团队已经在科研、金融、工业、医疗等领域探索这套方案的落地。